
This jumpstart deploys a stateful stream processing demo using Spark Structured Streaming with RocksDB hosted on OneLake into your Microsoft Fabric workspace.
Getting Started
After installing the jumpstart, visit the companion website to create heartbeat producers and consumers right in your browser.
Architecture
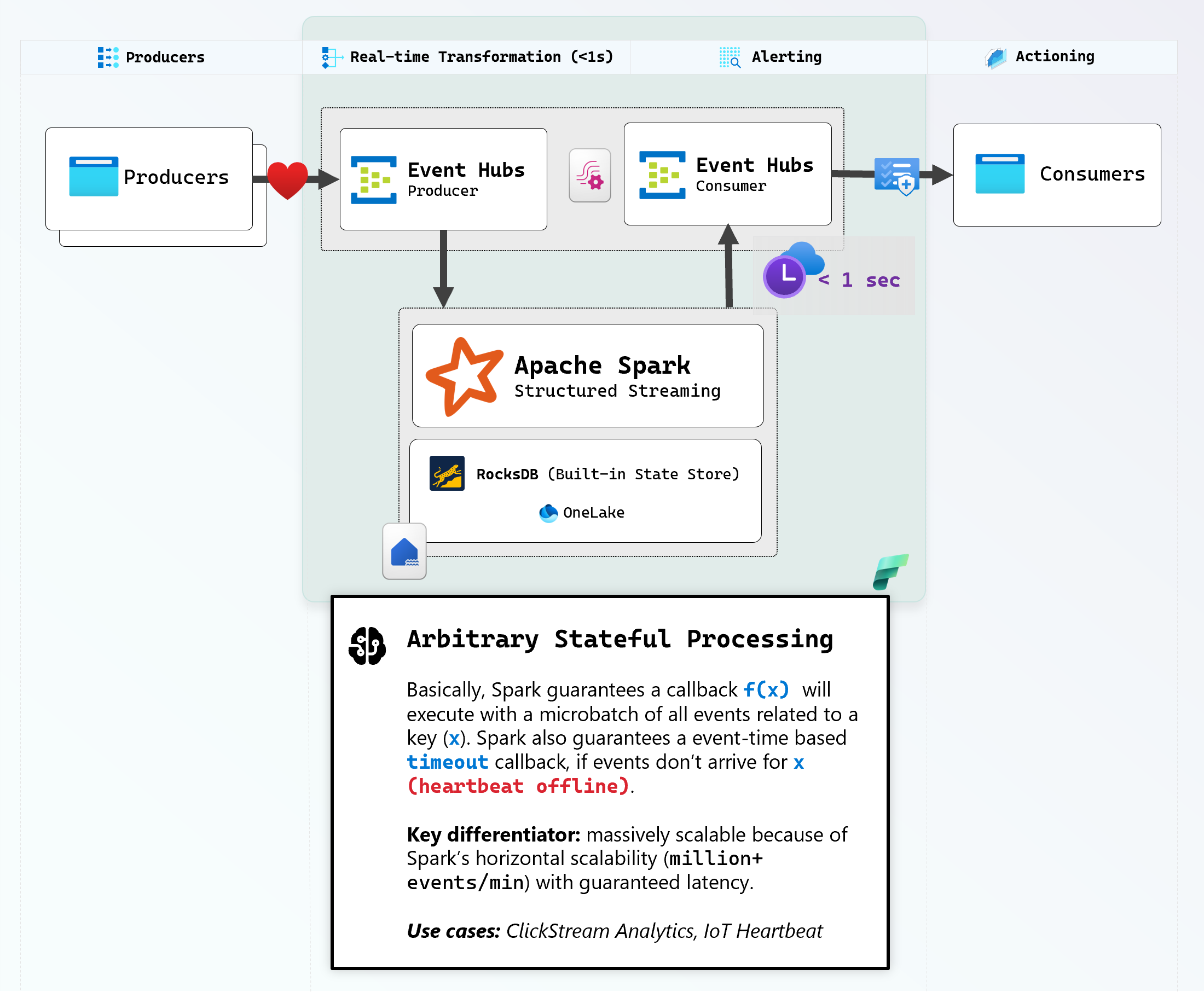
How It Works
- Producers on the website send heartbeat events every second
- Spark groups events by
machine_nameand tracks state transitions using RocksDB - State machine:
None → Initializing → Healthy ↔ Unhealthy (on 5s timeout) - Only emits output when state changes, not on every heartbeat. This allows us to effectively treat RocksDB as a distributed buffer so we get notified on interesting events at low latency.
- Pause a producer to watch it go Unhealthy after 5 seconds
Browser Producer Client to Event Hub
The browser uses an EventHubProducerClient, which adds a single message to a batch and sends it to Event Hub for this simple demonstration every second. To maximize throughput and avoid socket exhaustion, the best practice would be to add as many messages as possible, until the batch limit is reached - see TryAdd.
The client can durably control the partition the event will end up in by specifying a PartitionKey. Note that this is NOT the actual partition ID, but rather, providing a hint to the Event Hub SDK in the form of a string, that will be hashed so all events with this hash are guaranteed to route to the same partition.

Spark parallelized MicroBatch Ingestion from Event Hub
The Event Hub SDK implements the Spark RDD interface in EventHubsRDD, which uses local threadpools per Executor to dequeue messages from the Event Hub as fast as possible within a Microbatch.
There are a large number of tunables the end-user can set to control the behavior of the Spark Executor during ingestion.

Spark Stateful Processing with RocksDB
Extremely low latency is reached on a small Spark Cluster for this demonstration by setting Shuffle Partitions to 1. To yield events when a producer goes offline, the stream is GROUPED BY the unique producer identity (in this case machine_name), and a State Machine function heartbeat_state_transition iterates in parallel per microbatch callback on incoming data per key (machine_name), to implement further business logic.
State from the above GROUP BY is stored transparently in RocksDB, a highly performant Key:Value database with concurrent flush support, and durability guaranteed by Object Store (in this case, OneLake). Upon stream crash/shutdown, Spark is able to reconstruct previously stored state from RocksDB and resume processing where it left off, without data loss and with minimal downtime. By using event time for the watermark, we're able to ensure that even if the Stream goes down for several days, we continue on with the calculation upon restart without sacrificing correctness - see RocksDBStateStoreProvider.
This pattern scales extremely well, because each Spark Job is guaranteed to own it's checkpoint folder, therefore each Spark Job has it's own personal database to scale arbitraily high. Given the large throughput and concurrency gurantees of OneLake, this patterns scales near infinitely via horizontal scaling.

| # | Scenario | State Store to use | Why |
|---|---|---|---|
| 1 | Application with no stateful query | None | Spark Streaming doesn't need a state store unless you have stateful operators (GROUP BY, SUM etc.) |
| 2 | Application with stateful query | RocksDB | The HDFS-backed State Store Provider loads all data into memory, you can reach Garbage Collection (GC) pressure on the heap |